By Pierre Laforgue, Alex Lambert, Luc Brogat-Motte, Florence d’Alche-Buc.
In Proceedings of the 37th International Conference on Machine Learning (ICML), Online, PMLR 119, 2020.
https://arxiv.org/pdf/1910.04621.pdf
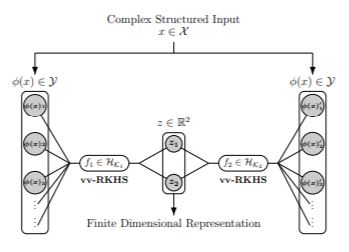
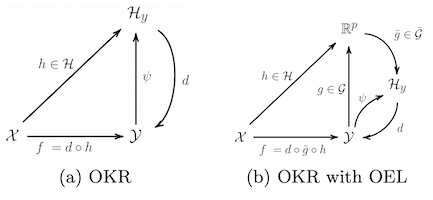
Abstract. Operator-Valued Kernels (OVKs) and associated vector-valued Reproducing Kernel Hilbert Spaces provide an elegant way to extend scalar kernel methods when the output space is a Hilbert space. Although primarily used in finite dimension for problems like multi-task regression, the ability of this framework to deal with infinite dimensional output spaces unlocks many more applications, such as functional regression, structured output prediction, and structured data representation. However, these sophisticated schemes crucially rely on the kernel trick in the output space, so that most of previous works have focused on the square norm loss function, completely neglecting robustness issues that may arise in such surrogate problems. To overcome this limitation, this paper develops a duality approach that allows to solve OVK machines for a wide range of loss functions. The infinite dimensional Lagrange multipliers are handled through a Double Representer Theorem, and algorithms for epsilon-insensitive losses and the Huber loss are thoroughly detailed. Robustness benefits are emphasized by a theoretical stability analysis, as well as empirical improvements on structured data applications.

![Investigating CoordConv for Fully and Weakly Supervised Medical Image Segmentation [pdf]](http://bibbase.org/img/filetypes/pdf.svg "paper")